特集2
IR室企画〈第2回〉 座談会
研究を〈測る〉とは?
話し手●井上雄介(国立国語研究所特任専門職員)+ 本多啓介(情報・システム研究機構 統計数理研究所主任URA、特任准教授)
聞き手●押海圭一(特任専門職員)+ 熊澤輝一(准教授)
シリーズ第1回めはInstitutional Research(IR)の基本情報や地球研でのIR活動の現状を報告した(71号)。これをふまえて今回は、情報・システム研究機構統計数理研究所の本多啓介さんと国立国語研究所の井上雄介さんとともに研究IRや大学共同利用機関におけるIRの役割について語りあった
押海●最近、世界大学ランキングに関する新聞記事などで、日本の研究力や研究の質が低下しているという記述をよくみかけます。しかしその裏には、そもそも研究力や研究の質とはなにか、という問題があります。そのヒントとして、研究評価に関する基本的なテキストである『研究評価・科学論のための科学計量学入門』*1に指標の機能の基本的な図式が掲載されています。それにあてはめると、研究力は測りたい「対象」にあたるが、直接測ることができないため、それを示すであろう「指標」のかたちで捉え直し、その指標にもとづいて定量的・定性的に研究力を測っているというのが現状です。そこで、具体的に国語研や統数研でどのような指標で研究力を測っているのかをお聞かせください。
「研究力」の測り方
井上●前任の琉球大学では、おもにアウトプット指標である、出版された論文の被引用数や掲載誌のインパクトファクターなどを中心に研究成果を測っていました。これらの指標は、Web of Science*2に掲載された論文を対象としていたため、そこに載らない日本語論文や書籍などにはつかえないことが問題でした。そこで、ほぼすべての研究者が応募することのできる科研費を中心とした競争的研究資金の獲得金額もインプット指標として測るようにしました。
本多●私は統数研でURA*3として産学連携や計算機の利活用を通じて、共同利用を推進する業務も行なっています。URAチームが新規にコーディネートする外部機関との連携が増えてゆくなかで、個別の案件に同時並行で対応するのがむずかしくなってきた時期がありました。そこで、こちらからテーマを設定して、そこに新規ユーザーを誘導して新たな統数研の共同利用ユーザー群のようなものができないかと考えるようになりました。URAはそのなかで彼らの研究に必要なデータ整備やシステム開発を支援すれば、これは統数研のファシリティである計算機の利活用にもなると。当時は第3期中期計画の策定時期で、評価のための指標が重要視され議論されているのをそばで見ており、あるときこれは統計学の研究テーマそのものになりうると思いました。
押海●研究テーマそのものになるとはどういうことでしょうか。
本多●つまり、客観的に評価をするための指標を研究するとか、データにもとづく意思決定に貢献することは統計学の対象そのものであり、統計学が大いに貢献できる領域であるということです。そこで、研究力や研究の質とはなにかということになると、たとえばインパクトファクターや被引用数などの標準的な指標では、統数研の貢献は測れないと考えています。統計学では、ある研究の貢献が顕在化するのに比較的長い時間がかかります。直近数年間の被引用数などでは研究者の貢献は測ることがむずかしく、研究業績の評価をロングタームで行なう必要があるからです。さきほどの指標の話にもあったように、測りたいものをきちんと決める必要があると考え、まずわれわれの立場として数学的な分野の研究力をきちんと測れて、さらに統数研のミッションである共同利用への貢献状況を可視化できる指標が必要と考えました。そのような状況で統計の研究者と共同研究プロジェクトをつくってゆくのを始めたのが2015年でした。
潜在的な研究分野がみえる?
押海●その共同研究と関連して、統数研が開発を進めておられるREDi(Research Diversity Index)と名付けられた異分野融合指標について、お教えいただけますか。
本多●数学や統数研の貢献を可視化したいと考えたときに、いかに多様な分野に貢献しているかを可視化できる指標をつくることを考えました。既存の指標では、分野間の比較がもっとも困難な点の一つであり、それをまず解決しなくてはいけないと考えました。そこで、分野の偏り・バイアスを取り除いたうえで新たに学術分野を規定するために、Web of Scienceのデータの引用ネットワーク全体を集計し、「確率的ブロックモデル」という手法をつかい、引用-被引用の関係の近いものは近く、遠いものは遠く並べ換えるというクラスタリング*4を行ないました。しかし、このような集計でも、論文の数が大きい学術分野とそうでない分野とで偏りが出るため、それを取り除くために「自己相互情報量(PMI: Pointwise Mutual Information)」を適用しています。
押海●PMIとはどのようなものですか。
本多●これは自然言語処理における単語間の共起確率を計算するためにつかわれるものなのですが、これをつかうことによって分野の偏りを補正してクラスタリングをし、できあがった各クラスターを「潜在的学術分野」と呼んでいます。これは、Web of Scienceなどで行なわれている、雑誌ごとにラベル化された分野ではなく、引用ネットワーク構造にもとづく分野です。このクラスタリングの結果をつかって、REDiを算出するのですが、一つの論文が別の論文に引用されたとき、その二つの論文が所属するクラスター間の距離、すなわち潜在的学術分野間の距離をつかって、離れた分野間はスコアが高くなるように算出します。
押海●REDiの開発状況についてお教えいただけますか。
本多●現在は、一つの論文を与えるとREDiを計算できるレベルまで実装できています。これからは、これをシステム化して人につかってもらえるための開発と、REDiの適用先として、まずは統数研の共同利用委員会で公募型共同利用として次年度の重点テーマ設定をするさいにつかってもらうことが決まっています。
押海●REDiの公開時期などは決まっているのでしょうか。
本多●公開するためにクリアすべき点が2つあって、一つは書誌データのライセンスの問題、もう一つはシステム開発面であと半年ぐらい必要と思っています。これは統数研が所属する情報・システム研究機構のプロジェクトの一環で、その計画では2019年度に公開予定です。
押海●地球研は学際研究や超学際研究をミッションとしているため、地球研の研究がどれぐらい学際的、超学際的なのかを見せる必要があります。そのときにREDiのような指標は学際性の可視化にたいへん役だつだろうと考えており、ひじょうに期待しています。
本多●公募型共同利用の選定のさいに、じっさいに機関の意思決定につかわれるということがとくに重要であると考えており、そのためにはたんに指標を開発するだけでなく、メソッドをあわせて考えることが必要です。論文が決まるとスコアは計算できますが、そのスコアを意思決定側の人間がどうつかってよいかわからないという状況があることをふまえて、どの論文を選ぶべきか、どのようにリポーティングすべきか、などをメソッド化することを考えています。
熊澤●REDiの技術的な面について、論文に付けられたタグを手がかりにその論文の分野を推論して分ける場合と、自己相互情報量を計算して偏りをなくす場合とでは、どのくらいちがいが出るのでしょうか。
本多●Web of Scienceのデータでは、それぞれの論文は掲載雑誌の分野に紐づけられていて、このパターンをすべて集計するとおおよそ3,000パターンくらいで、3,000×3,000の引用-被引用の関係表ができることになります。論文数が多い分野は引用数も多くなってしまうので、それをPMIで補正し、確率的ブロックモデルでクラスタリングして、よくつかわれている学術分野の大分野に近いくらいの規模として、25くらいのクラスターになるようにしています。より関係性が近いものは近く、遠いものは離れるというクラスターになり、その中身は、医学系は医学系、工学系は工学系のように、だいたい近い分野の論文が集まっていますが、そうでないものもあります。このクラスタリング結果は、あるジャーナルの出版元や書誌データベースを整備するキュレーターが決めた分野ではなく、出版後、その雑誌の論文群がどのような引用-被引用の歴史を経たかという情報をつかっていると言えます。その解釈をテキストマイニング*5などをつかって行なっているところですが、過去25年分くらいのデータをつかったクラスタリングではおおむね既存の学術分野とそれほど大きな乖離がない結果になっています。
熊澤●その意味では、ここでクラスターとして出てきた分野は、近い将来そのような分野構成になると考えられそうですね。
本多●このクラスターはどの期間のデータをつかうかで変わってくるのですが、その推移を見れば分野構成の変化を捉えることはできるかもしれません。
井上●これは引用側と被引用側でかなり変わってくると思います。たとえば、臨床医学の論文はおそらく臨床医学や基礎医学などの限られた分野からの引用がほとんどであると予想されますが、逆に統計学の論文などは基礎医学や工学、人社系の心理学などからも引用されるかもしれない。
本多●REDiでもともと見たかったのは、いかに異分野に影響をおよぼしたかという点であったため、どの論文を引用したかではなく、どの論文に引用されたかを見ています。どの論文を引用しているかという見方も可能とは思いますが、それをどう解釈するかはまだ検討の必要があります。
井上●引用した論文数と引用された論文数の差を取ることで分野ごとの引用の広さも見ることができるかもしれませんね。
人文社会系の研究の特性と客観的評価のむずかしさ
押海●次に、人文社会系の研究評価について、国語研の状況を教えていただけますか。
井上●国語研も統数研や地球研と同様に大学共同利用機関であり、共同利用・共同研究が最大のミッションです。国語研の研究活動は、国語研のプロジェクト、人間文化研究機構のプロジェクト、個人や科研費で行なったものの三つに分けられます。国語研のプロジェクトにおける研究業績の例として、コーパス*6の公開があります。これはたいへんな労力と時間をかけて行なっているのですが、コーパスをつくったことや基礎原理などは論文として発表されるかもしれませんが、コーパスそのものは論文ではありません。ですので、コーパスという成果を評価するさいに、論文の引用-被引用関係であるWeb of Scienceのデータに依存する評価方法はつかえません。また、著書・編書もひじょうに重要な業績であり、なかにはWeb of Scienceに収録される書籍もあるかもしれませんが、書籍の被引用データは収録されていないため、定量的な評価が不可能です。
押海●理系と同じような評価はむずかしいということですね。
井上●さらに、国語研では医学における疫学調査のように、日本語に関する継続的・定点的な社会調査を行なっており、そのデータは大量に紙などのアナログの形で保管されています。それらのデータは、言語資源としてとても重要な研究成果ですが、その多寡で研究成果の質を評価することはできません。たとえば、国語研に言語資源が50箱あり、ほかの大学には100箱あるから100箱のほうがよい、という単純比較はできません。このように、引用関係で計算することのできない業績や、数値化できない業績があるため、客観的な評価がむずかしいという現状です。私も琉球大学に在籍していたころから、人文社会系の研究をどう評価するか、比較可能な客観的な指標としてどのようなものが考えられるか、ということを考えてきたのですが、やはりむずかしさを感じます。それは理系でつかわれている被引用数などをもつ業績の数が少ないことが原因で、そのように最初からほかと比較することが可能な数値が少ない状況でなにができるか、ということが問題です。
本多●いま言われたことは人文社会系の研究者の評価だけに限らないと思います。たとえば統数研の研究者でも、国際研究集会をオーガナイズするなど研究者の活動はさまざまです。『地球研ニュース』71号で押海さんが、指標の活用の目的が不明確であるという問題点を指摘されていますが、いまの指標の話は研究者個人の評価や研究機関の活動のアピールという目的での話だと思いますので、客観的な評価がむずかしい指標しか挙がってこないという問題だと思います。
押海●2015年に出たMetric Tide*7という研究評価指標に関する報告書には指標やそれらを取り巻く状況が包括的に書かれています。英語ではこのような報告書やガイドラインはけっこう出ており、だいたいの結論としては、一部の指標に偏ることなく、なるべく多くの指標を適切に選び、評価を行なうことが必要であると書かれています。しかし、研究評価に割くことができる人的・金銭的リソースが充分にないとそのような評価はむずかしい。また、評価への利用に耐えうるきちんとしたデータを各大学や研究機関が独自に準備することはむずかしいために、商用データベースのデータを購入して使用せざるをえない現状も問題だと思います。
大学共同利用機関のIRの役割
押海●大学共同利用機関のIRは、大学とはかなり状況が異なっています。大学であれば教学IRや評価関係のIRが中心となりますが、こちらには学部生がいないため教学IRは必要ありません。しかし、研究IRや共同利用・共同研究のためのIRといった観点は必要になると思います。本多さんのおっしゃるように統数研では共同利用の推進をIRの重要なミッションとされていますが、国語研はいかがでしょうか。
井上●日本語に関する大規模な社会調査は国語研でないとできません。そのような社会調査もふくめて、ほかの大学などではできないことをするのが大学共同利用機関の役割の一つであると考えています。また、そこで集めた資源をほかの大学の研究者が活用するということが、理系の論文でいう被引用に相当するのではないかと思いますので、その可視化はIRの重要な役割でしょう。
熊澤●人文社会系の研究評価のあり方としては、数に頼らない評価方法を検討する必要があるように感じます。
井上●数に頼らない評価も重要ですが、数そのものも重要と思っています。しかし、各教員の個別の評価を足したものが国語研の評価ではなく、国立大学法人法にもとづいて定められた国語研のミッションに対してどれだけ貢献・達成ができているかが国語研の評価であり、国語研のIRが考えなければいけない点なのだと思います。
熊澤●そのミッションは大学ではできないミッションということですね。
井上●国語研で第4期の目標を考えるさいには、論文の被引用数や科研費獲得額などの外的要因に作用されうる数値を横目で睨みつつも、所内の努力で達成できる種類の目標であり、かつ、うまく数値化できるようなものを指標に加えるべきと考えています。そして、その数値化できる指標を見つけて、それが客観的かつリーズナブルであるということを文科省や世間一般の方がたに伝えるというのがIRの役割であろうと考えています。
本多●統数研からこのプロジェクトの評価項目として出している指標は、開発した指標の大学の利用件数など数がはっきりしているものを選んでいます。目標値の算出根拠などはいろいろ考えて出すのですが、その目標値がリーズナブルであるかどうかを説明するのはとてもむずかしいことです。ただし、私は評価指標の設定やそのためのデータ収集はIRの仕事の一部と思っていて、意思決定や戦略策定に貢献し、研究を発展させ、予算を獲得し、研究所を強く、大きくすることがもっとも重要なIRの仕事であると考えています。また、統数研としては、人文社会科学の研究評価のさいに論文データがないとか被引用データがつかえないという問題があるのであれば、いっしょに問題解決のために共同研究などできればと考えています。URAはそういう新規の課題に研究者を引き込んでコーディネートすることが本来の仕事です。今後、第4期中期計画策定のさいには各大学共同利用機関間のIR担当者やURAが積極的に連携して情報交換することも重要だと思います。
押海●地球研も今後さらにIRを意思決定や戦略策定に活かせるよう、体制整備や所内意識の改革に努めたいと思っています。また、地球研は学際研究、超学際研究などを実施する実験的な研究機関でもありますので、統数研や国語研などとのIRを通じた連携を強化し、学際研究や超学際研究の評価、人文社会系の研究評価などのモデルケースとなれるよう努力したいと思います。本日はありがとうございました。
〈2018年8月9日、国立国語研究所にて〉
*1 調麻佐志ほか『研究評価・科学論のための科学計量学入門』丸善、2004年
*2 クラリベイト・アナリティクス(Clarivate Analytics:旧トムソン・ロイターThomson
Reuters)が提供する学術論文や学術図書を中心としたオンラインデータベース。書誌的事項のほかに引用文献データも索引化されており、ある論文がどの論文で引用されているのかがわかる。関連文献を検索することで、研究のながれや重要度・影響度が調査できる。
*3 大学などにおいて研究者とともに研究活動の企画・マネジメント、研究成果の活用促進に取り組み、研究活動の活性化や研究開発マネジメントの強化などを支える。
*4 機械学習で用いられるデータ分類手法で、与えられたデータのみからデータの背後の構造を抽出する場合に用いられる。
*5 文字列を対象としたデータマイニング。文章データを単語や文節で区切り、その出現の頻度や共出現の相関、出現傾向、時系列などを解析して有用な情報を取り出す。
*6 言語学において、自然言語処理の研究に用いるため、自然言語の文章を構造化し大規模に集積したもの。用例にもとづいた文章解析や、コーパスを学習させて文法や語の概念などのモデルの作成などにつかわれる。
*7 Wilsdon, J., et al. “The Metric Tide: Report of the Independent Review of the Role of
Metrics in Research
Assessment and Management,” DOI: 10.13140/RG.2.1.4929.1363, 2015

指標の機能(基本的な図式)
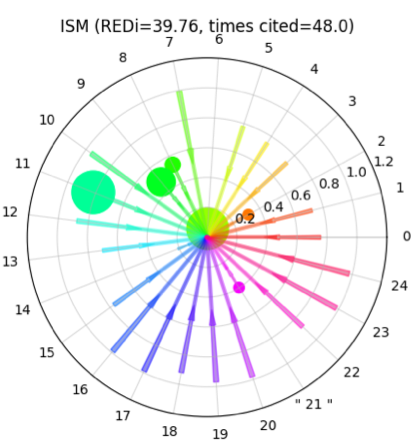
一つの論文のREDiを視覚化したもの

井上さん

熊澤さん

本田さん

押海さん

いのうえ・かつゆき
大学共同利用機関法人 人間文化研究機構 国立国語研究所 IR推進室 特任専門職員。現在の専門は研究評価・IR。2013年新潟大学研究企画室URA、2015年琉球大学研究企画室 主任URAを経て、2018年から現職。
ほんだ・けいすけ
大学共同利用機関法人 情報・システム研究機構 戦略企画本部 URAステーション、統計数理研究所 運営企画本部企画室。URAステーション 主任URA、特任准教授。2013年12月から統数研に在籍。
おしうみ・けいいち
地球研IR室特任専門職員。専門は法学︎。2011年から地球研に在籍し、2015年7月より現職。地球研らしさをデータからみる方法を模索中。
くまざわ・てるかず
専門は環境計画。地球研研究基盤国際センター准教授。2011年から地球研に在籍。